
SemaLogic
= Symbolische Logik, wissenbasierte Modelle und generative KI
(Hybrid Artifical Intelligence - HAI)
- gemeinsam denken -
(Logik)Sprache SemaLogic
- Symbolische KI -
SemaLogic basiert auf einem generischen und wirkungsvollen Konzept. Es kombiniert logische Terme und einfache mathematische Operationen in symbolischen Regelwerken. Durch die eindeutige Verknüpfung von Textquellen und logischen Aussagen ist die Verarbeitung nachvollziehbar, erklärbar und vollständig transparent. Dabei werden Regelwerke versioniert, Werte und Ausdrücke durch Intervalle präzisiert sowie dynamische semantische Gruppen ermöglicht. Zudem lässt sich SemaLogic durch nutzerspezifische Dialekte flexibel an jede natürliche Sprache anpassen.
Mit der patentierten formalen Spezifikationssprache SemaLogic können logische Informationen in semantischen Regelwerken jederzeit nachvollziehbar und sicher aus Texten herausgelesen, direkt geprüft und grafisch verständlich dargestellt werden. SemaLogic repräsentiert beliebige Regelwerke in einer präzisen, maschinen- und menschenlesbaren Sprache und beschreibt damit den vollständigen logischen Lösungsraum – von der Cloud bis zum Sensor im Smart Home. Ob Studienordnung, Fertigungsstraße, Energiemanagement oder Chatbot-Dialog: Überall dort, wo klare Regeln zur Steuerung verwendet werden, sorgt SemaLogic für Konsistenz, Nachvollziehbarkeit und Audit-Sicherheit. Zeitliche bzw. Vorgänger- und Nachfolgebedingungen ergänzen, die Regelwerksdefinitionen.
Die Technologie ist domänen- und plattformunabhängig. Einmal formulierte Regeln können in Edge-Geräten, Cloud-Diensten oder industriellen Steuerungen wiederverwendet werden und lassen sich jederzeit erweitern. SemaLogic kann als universelle Basis für Automation, Compliance und interaktive Systeme verwendet werden.
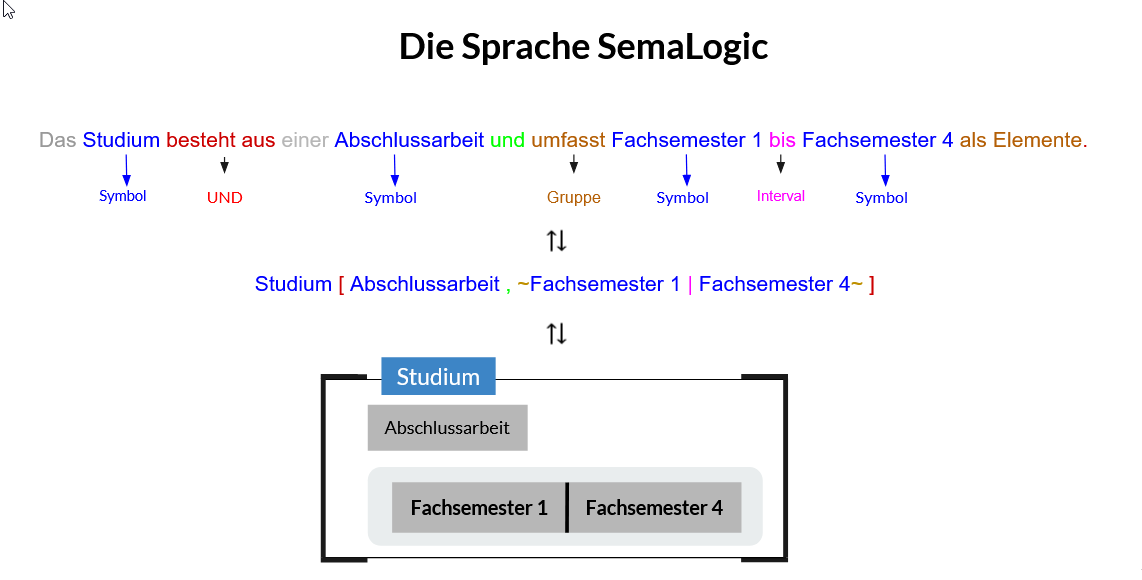
Die folgende Abbildung zeigt die Äquivalenz der formalen Sprache SemaLogic mit ihrer technischen Interpretation sowie ihrer für Menschen schnell begreifbaren visuellen Darstellung der Regelwerke.
SemaLogic zum Ausprobieren
In Kürze finden Sie hier einen Webservie, mit dem Sie SemaLogic direkt als Webservice ausprobieren können - einfach Text eingeben und prüfen lassen, ob er logisch korrekt ist.
Konstruktion der Sprache SemaLogic
Welche Sprachstrukturen kennt SemaLogic und wie kann SemaLogic logische Prüfungen von semantischen Regelwerken ohne natural language processing durchführen ?
Wissensbasierte
KI-Modelle
Durch die Ontologie-basierte Klassifikation können Bedeutungen von Objekten definiert und zueineander in semantische Beziehung gesetzt werden.
Innhalb der sich daraus aufbauenden Knowledge-Graphen ergeben sich nicht nur Beschreibungen von Klassen, sondern der Kontext der jeweiligen Bedeutung kann durch umgebenden Beziehungen bestimmt bzw. eingeordnet werden.
Generative KI
Large Language Modelle (LLM) sind Wahrscheinlichkeitsmodelle, die aufgrund angelernten Wissen eine Repräsentation eines Sprach- bzw. Wissensmodells beinhaltet und damit in der Lage sind, Texte zu generieren und zu analysieren.
Die hohe Sprachkompetenz und die Vielseitigkeit bei der Beantwortung von Fragestellungen sind eindeutige Vorteile dieser Modelle. Mangelnde Verlässlichkeit (z.B. Halluzination), ihre Intransparenz der Entscheidungsfindung sowie die Verstärkung von Vorurteilen der Trainingsdaten erschweren allerdings ihren Einsatz in vielen Einsatzszenarien.
Als hybride KI kann SemaLogic nahtlos mit Large Language Models (LLMs) verbunden werden. LLMs generieren Varianten, die SemaLogic formal prüft und so regelkonforme Ergebnisse garantiert.
Semantische Dokumentenanalyse
Große Dokumente beinhalten "versteckte" Wissens durch ihren strukturellen Aufbau als auch eine unterstellte Interpretation von genutzten Begriffen und Sinnzusammehängen.
Durch die Kombination von wissensbasierten Modellen und einer automatisierten Nutzung generativer KI sowie additiv impliziter semantischer Regeln symbolischer KI können sehr viel bessere automatisierte Ergebnisse bei der Dokumentenanalyse erzeugt werden. Klare Quellnachweise trotz Nutzung generativer Modelle, Vermeidung von Halluzinationen, Verknüpfung des impliziten Wissens aus der Dokumentenstruktur sind nur einige Vorteile der KI-Kombinatorik.
